[ORACLE] 분석함수에서 FIRST/LAST 함수 사용하기
반응형
예시 테이블
SQL> select * from t;
C1 D1 D2
---------- ---------- ----------
1 1 1
2 2 2
3 0 3
4 1 4
5 2 0
6 0 1
7 1 2
8 2 3
9 0 4
10 1 0
11 2 1
C1 D1 D2
---------- ---------- ----------
12 0 2
13 1 3
14 2 4
15 0 0
16 1 1
17 2 2
18 0 3
19 1 4
20 2 0
20 rows selected.위와 같은 테이블에서 분석함수 + FIRST / LAST 함수를 사용해보자.
FIRST 함수 + 분석함수
SQL> SELECT MIN(C1) KEEP (DENSE_RANK FIRST ORDER BY D1) OVER (PARTITION BY D2) FIRST FROM T;
FIRST
----------
15
15
15
15
6
6
6
6
12
12
12
FIRST
----------
12
3
3
3
3
9
9
9
9
20 rows selected.T 테이블을 대상으로
d2 컬럼을 기준으로 파티션을 나눔
d1 컬럼을 기준으로 정렬한 후 첫번째 값들 추출 (FIRST)
그중 C1의 값이 제일 작은 값을 추출 (MIN)
위 글을 그림으로 나타내보면,
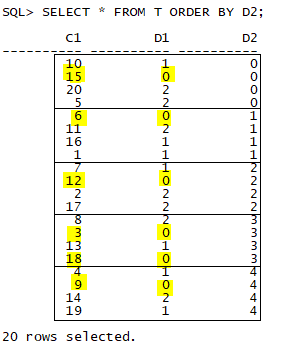
파티션이 나뉘고 FIRST 함수에 의해서 D1이 제일 작은 값을 선택함 ( 노란색으로 색칠된 행 )
3번째 파티션에는 D1의 값이 0으로 겹치는 행이 2개 존재한다. 이 중 MIN(C1) 함수에 의해 3의 값이 출력된다.
마찬가지로 LAST 함수를 사용해보자
SQL> SELECT MIN(C1) KEEP (DENSE_RANK LAST ORDER BY D1) OVER (PARTITION BY D2) LAST FROM T;
LAST
----------
5
5
5
5
11
11
11
11
2
2
2
LAST
----------
2
8
8
8
8
14
14
14
14
20 rows selected.T 테이블을 대상으로
d2 컬럼을 기준으로 파티션을 나눔
d1 컬럼을 기준으로 정렬한 후 마지막 값들 추출 (LAST)
그중 C1의 값이 제일 작은 값을 추출 (MIN)
위 글을 그림으로 나타내보면,
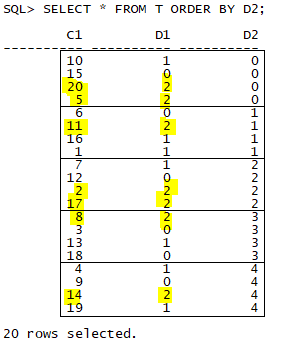
파티션이 나뉘고 LAST 함수에 의해서 D1이 제일 큰 값을 선택 ( 노란색이 색칠된 행 )
1, 3번째 파티션에서 겹치는 값이 존재하여 MIN(C1) 에 의해 5, 2가 선택된다.
반응형
'⇥ DevOps Tech 🙋🏻♀️ > ✏️ ORACLE' 카테고리의 다른 글
| [ORACLE] 오라클 19c 설치 방법 (0) | 2021.11.19 |
|---|---|
| [ORACLE] 집합 함수 (AVG, COUNT, SUM, MAX, MIN, RANK, DENSE_RANK, LISTAGG) (0) | 2021.05.28 |
| [ORACLE] 설치 된 상태에서 재설치 하는 방법 (0) | 2021.04.27 |
| [ORACLE] WALLET OPEN 방법 (0) | 2021.04.26 |
| [ORACLE] 삭제 (DELETE) (0) | 2020.08.31 |